
This no excuses post has been a long time coming. One of the things that most librarians have in common is that they are long-suffering, friendly, helpful, accommodating types, ready to share knowledge, know-how and eager to grasp on any acknowledgement they receive from academic leadership and fellow teachers. While the grumbles and moans are prolific within our little echo chambers, few of us have the time or energy to actually be vocal. We’re generally just grateful we have jobs, in a market where libraries and librarians are sacrificed a the altars of economies and “it’s on the internet”. So many just put up and shut up. And are careful of the swords we’re prepared to fall on.
In the mean time, there are people and companies in this academic / learning / research space who are making a lot of money and who do get heard / listened to. If you read only one article about this, I’d recommend the Guardian Long Read : “Is the staggeringly profitable business of scientific publishing bad for science?” I’d love to ask if the profitable business of school databases is bad for research and learning.
So the saga began at the end of the last academic year. I was teaching academic honesty to my Grade 4’s and they were just about at the point of grudgingly agreeing that it was a good idea (in IB PYP speak) to have “integrity, respect and appreciation” for other’s work and be “principled” in acknowledging where the images they were using in their research were coming from.
In order to limit their going too wildly astray on the world wild web, the teachers and I agreed that we’d limit the images they used to two sites – the paid Britannica Image Quest (available to schools as part of the school version of Britannica bundle for a mere US$6,000 per year depending on your size), and the unpaid “photosforclass” where the attribution is included in the photo watermark and they make an effort to ensure the photos are school appropriate and are under creative commons license.
So far so good until we got to the point of looking at the citations created by – no not the free tool but the really expensive one!
As we looked up the various things students were researching to my utter dismay I realised that each and every one had as creation date 25 May 2016.
One of the things that I try to keep in the back of my mind when teaching information literacy is where we are going in terms of threshold concepts. We want to ensure that students are not going through the rote / skill part of academic honesty without really understanding the bigger information literacy picture.
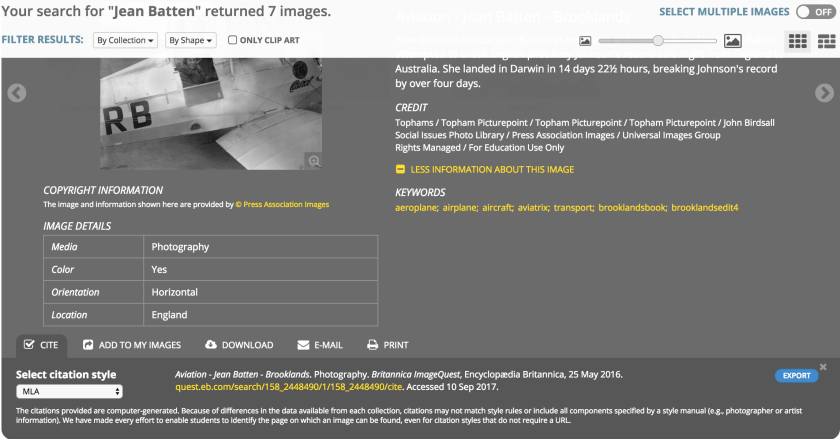
So I wrote to our “local” Britannica representative questioning the date on the image. Surely it couldn’t have been May 2016? And who was the photographer? Surely they deserved a mention?
The correct structure for MLA8 (the system our school is using) is:
Creator’s last name, first name. “Title of the image.” Title of the journal or container that the image was found on, First name Last name of any other contributors responsible for the image, Version of the image (if applicable), Any numbers associated with the image (such as a volume and issue number, if applicable), Publisher, Publication date, Location. Title of the database or second container, URL or DOI number.
So the response I got back from Britannica was:
Many thanks for your email expressing your concern over our citation. I am guessing you are referring to the MLA format. We follow the required format for online publishing which does not require that particular information.
Example below.
HIV viruses (red). Photography. Britannica ImageQuest, Encyclopædia Britannica, 25 May 2016.
quest.eb.com/search/132_1274904/1/132_1274904/cite. Accessed 16 May 2017.MLA citation requires a publication date which is considered a core element of the citation. That, of course, would be the date of the last image publish of that collection, May 25, 2016. Because the data from the images comes from more than 60 collections, it is very inconsistent or we don’t have it at all. Britannica tries never to provide information that we cannot guarantee to be correct. We suppress this from the site for that reason.
http://quest.eb.com/collections
I hope this assists your understanding of our difficulty here. Please come back to me if I can be of more assistance.
At which point I cried foul. And took my concern to a couple of librarian networks. Where it was roundly ignored. Or where it wasn’t ignored it was met with a powerless sigh. And I wrote back to them as said no, I was not satisfied with that. Are you serious? They get photos from 60+ databases and can’t be bothered to spend a few dollars on mapping the available data properly to their database? Only 60? That means you pay 60 something people, one to look at each of those databases and work out their tagging and map it to your tagging. And then you pay somebodies to manually sort out the ones that don’t map nicely or you default to the cop-out citation for those. In the world of cheap accessible outsourced IT, that should be a no brainer. The entry about the privately owned Britannica on Wikipedia is illuminating.
In the world of fake news and fake photos and fake evidence and fake research and fake everything we need to be vigilant. When original primary research documents and images get scanned into databases we lose a trail if the creators and dates are no longer considered important enough to add. We are not talking about born-digital images here.
So I persisted and got this response:
Well you have certainly stirred thing up, in a good way I think. J
I’d like to share with you some of what has occurred since your concern was raised, in the hope it will be interesting and helpful in the future.
Our Editorial Team was consulted and they will be handling citations going forward. They did a full review of the MLA format and consulted with the MLA Handbook 8th Edition.
As I mentioned in a previous email, the reason we leave off the photographer is because the data we get from the partner is not in a format that would allow us to list it correctly on a consistent bases. The MLA Handbook states, “When a work is published without an author’s name. . .skip the author element and begin the entry with the work’s title” (p. 24). Since we cannot accurately list it, we are leaving it off. The editorial team are going to explore this a bit more and see if there is a way we can improve this, but for now we will leave it off. This will not be an easy thing to fix.
We are listing the publish date of the images (in addition to accessed date). According to the MLA Handbook, the publish date is appropriate. Because we didn’t always store the publish date in the database, when we revised for MLA 8 we had to fill in something so all images would have a date. We used the date of the most recent publish. From the point of making this change and going forward we now list the actual publish date of image. Since this did result in most, but not all, of the images having the same date we are going to go back and try to update the publish dates with the date the collection was first published on our site. This will hopefully make it easier to teach students what this date is for since the majority will not be the same. However just to reiterate, as new images are published they are now listing their actual publish date.
Over the next month or so, the Editorial Team will also complete a review of the other citation formats in ImageQuest and we will make changes as time allows. We will also create a citation page where we provide additional information to clarify our citation policy.
Nadine, I do hope it is clear that Britannica always endeavours to provide the most accurate information possible and that we do react, where we can, to try and improve on a valued customers suggestion.
and in fact, if you look at the bottom of every citation you’ll now see the following:
“The citations provided are computer-generated. Because of differences in the data available from each collection, citations may not match style rules or include all components specified by a style manual (e.g., photographer or artist information). We have made every effort to enable students to identify the page on which an image can be found, even for citation styles that do not require a URL.”
Why does this still bother me six months later? Let’s return to what we really want students to know about Information Literacy. What will carry them beyond their latest assignment, their Personal Project, their Extended essay. What will take them through life as sceptical consumers of information. Let’s go back to understanding the threshold concepts of information literacy.
We should rely on information that has authority. So we check the credentials, experience and expertise of those giving the information. There is an image of a young woman and a claim she broke an aviation speed record in 1934. Who took that photo? Where was it taken? When was it taken? Was she leaving or arriving? If the photo was taken on another day or time was it just posed? Was that the triumphant photographic proof of her exploit?
Information has a format. And it’s format is related to its creation, production and dissemination, NOT how it is delivered or experienced. Usually this is considered when comparing journal articles in a journal in a database to the journal format of the past as in volumes of books. The fact that the format is now online, doesn’t impact on the fact that it’s a a peer reviewed journal article. A similar argument can be made for a historical photo. The fact that it’s now delivered digitally shouldn’t ignore the fact that it was once a photo taken with a camera at a point in time by a real photographer.
Information is a good (as in goods and services). As such there is a value and a cost to information, and we should be aware of that. At the moment the balance of financial cost and reward seems to be very one sided. Databases buy up collections of information, bundle it, and sell it on at a premium and add as little value to the images as they can get away with. Usually just giving information on the seller rather than the creator of the images. The information structure – information is structured and accessed / searched in a certain way and that differs depending on the format and container.
The research process builds on existing knowledge. But if we ignore the existing knowledge and process whereby we get to the current point we’re negating this aspect. This also builds into the idea of scholarly discourse – that we’re entering an academic conversation at a certain moment.
So at this point I’d still be saying – no excuses. The fact that something is hard should never be an excuse not to do it properly. Yes they are right – they are complying with the MLA8 structure. But they are not helping with the spirit of scholarship and information literacy.

This is a fascinating look at how outdated information can be presented as current.
LikeLike